
In this project I analyzed a fitness center's attendance data to predict attendance rates of its group classes.

The tweet that started the trend was posted on June 12 (Philippine Independence day). On that tweet, the author stated that he dined in at a Tropical Hut branch, and he is their only customer. Despite the pandemic “restrictions”, commercial activity on malls and fast food chains are pretty much back to “normal”, so having only one customer is disheartening.

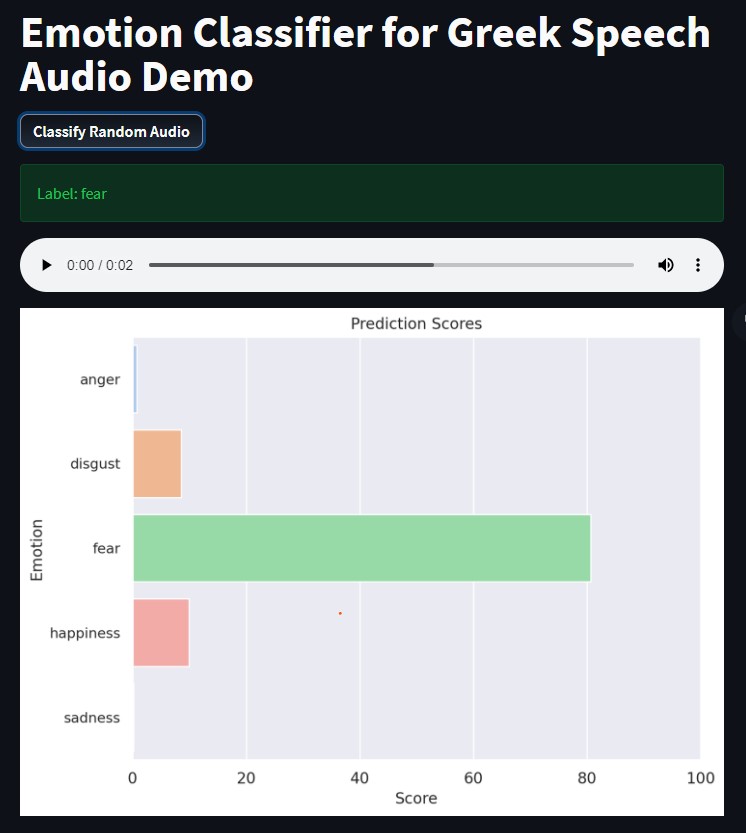
In this article, we will build a simple deep learning based demo application that can be accessed publicly in Hugging Face spaces

The rate at which unreliable news was spread online in the recent years was unprecedented. In this project, I finetuned some language models to make an unreliable news classifier.