
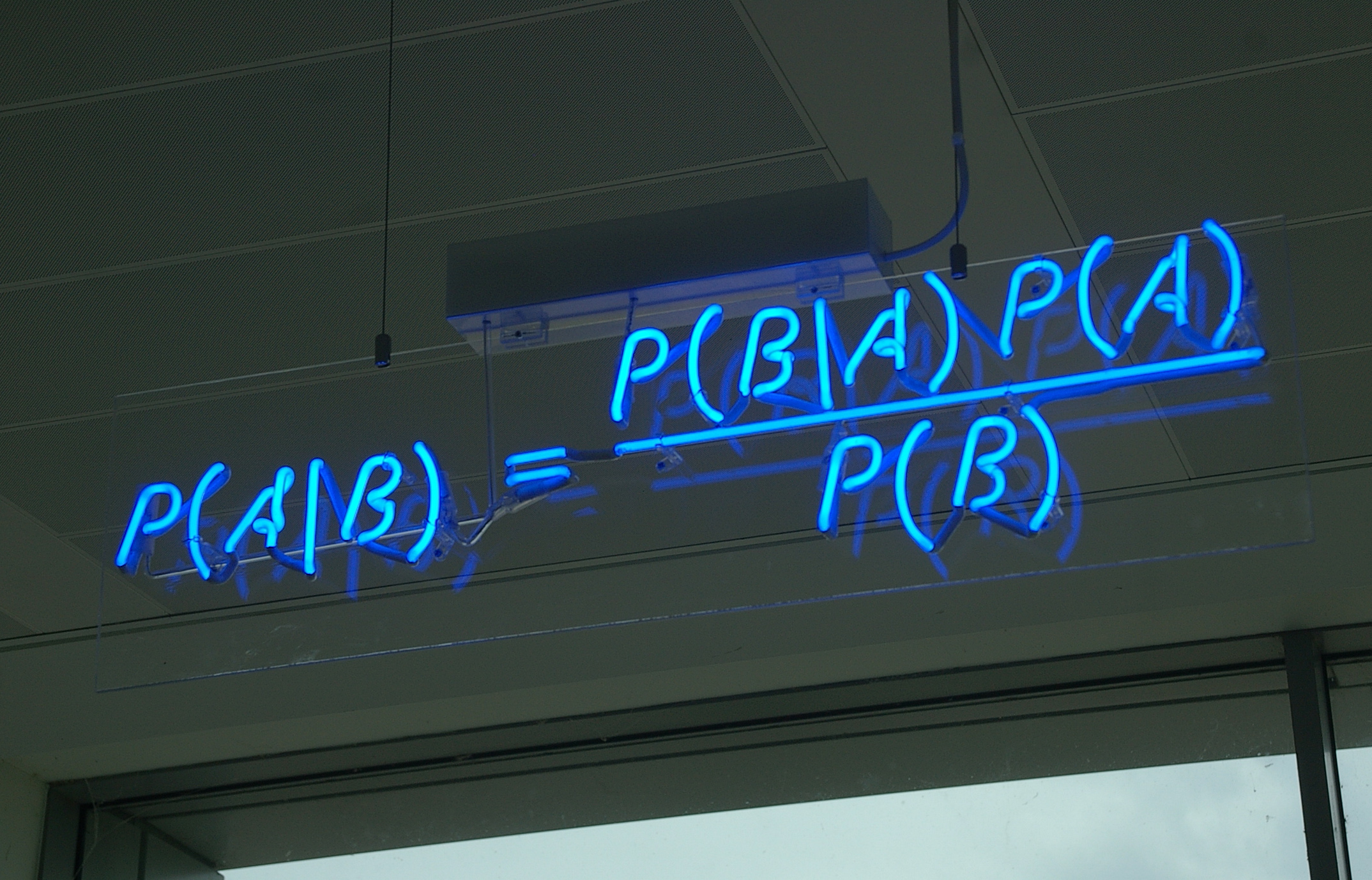
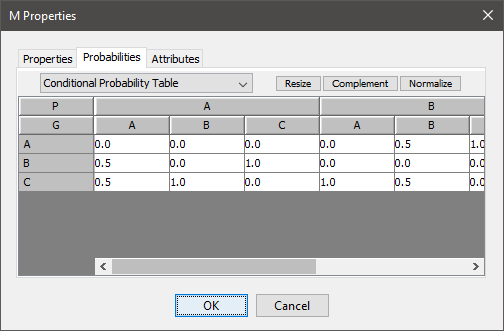
However, to make it a little bit more scalable, the tables are defined in a separate Google sheet, and imported into the Google Colab notebook. Each node is a separate worksheet, and the columns list the parent nodes, the name of the node, and probability.

In this article, we will build a simple deep learning based demo application that can be accessed publicly in Hugging Face spaces

In this article, I fine-tuned a pre-trained object detection model using a small custom dataset.

Code This case study is my capstone project for the Google Data Analytics Certification offered through Coursera. I was given access to …

Master predictive modeling with Scikit-Learn pipelines. Learn the importance of feature engineering and how to prevent data leakage.

Ready to dive into data science? Learn how to set up your development environment using Docker for a seamless and reproducible workspace. Say goodbye to compatibility issues and hello to data science success!
Bayesian Networks are a compact graphical representation of how random variables depend on each other. It can be used to demonstrate the …

In this project I analyzed a fitness center's attendance data to predict attendance rates of its group classes.

Build an Automated ETL Pipeline. From setting up Docker to utilizing APIs and automating workflows with GitHub Actions, this post goes through it all.

In this article, we will discuss how to quickly showcase your model publicly as a machine learning application for free.

The tweet that started the trend was posted on June 12 (Philippine Independence day). On that tweet, the author stated that he dined in at a Tropical Hut branch, and he is their only customer. Despite the pandemic “restrictions”, commercial activity on malls and fast food chains are pretty much back to “normal”, so having only one customer is disheartening.

In this short project, I scraped all of Lebron's regular season points and plotted them in an interactive graph.