Using BigQuery API in Python
Interacting with Google BigQuery necessitated the creation of a service account. This will also generate credentials as a JSON file. These credentials were stored and loaded dynamically, ensuring that the keys are not comitted to the repository. I have added a 'date_pulled' column, appended to the data fetched from the top airing anime endpoint. This column is used to prevent duplicate uploads and minimize unnecessary API calls.

Getting the top 50 airing anime for the day only takes 1 API call. Getting the details for each anime however, takes 1 API call for each. I use BigQuery to look for all myanimelist_id stored in my top airing anime table that doesn’t have a corresponding row yet in my anime details table. Except for the start of a new season, only a few anime will enter and exit this list so the API request for anime details will be lessened as the season progresses.

Data Processing using Pandas
Pandas, a Python library for data processing, is used to transform and clean the JSON response of the API. Nested fields were flattened, and values in the “list of dictionaries” format were simplified just be a comma separated string of names. Sometimes, an anime ID will not yet have details available so the API will return an error. These rows will not be added to our data. To simulate a data store, processed data was saved as Parquet files. Then a different function reads these Parquet files and uploads them to BigQuery.


Master predictive modeling with Scikit-Learn pipelines. Learn the importance of feature engineering and how to prevent data leakage.

Ready to dive into data science? Learn how to set up your development environment using Docker for a seamless and reproducible workspace. Say goodbye to compatibility issues and hello to data science success!

In this short project, I scraped all of Lebron's regular season points and plotted them in an interactive graph.

In this project I analyzed a fitness center's attendance data to predict attendance rates of its group classes.

A marketing agency presents a promotional plan to a telecommunication company to increase its subscriber base and generate revenue. Using population and location data, we estimated the feasibility of this plan in this case study.

The tweet that started the trend was posted on June 12 (Philippine Independence day). On that tweet, the author stated that he dined in at a Tropical Hut branch, and he is their only customer. Despite the pandemic “restrictions”, commercial activity on malls and fast food chains are pretty much back to “normal”, so having only one customer is disheartening.

In this project I trained a transformer model to recognize words from audio.

In this article, I fine-tuned a pre-trained object detection model using a small custom dataset.

In this article, we will build a simple deep learning based demo application that can be accessed publicly in Hugging Face spaces

The rate at which unreliable news was spread online in the recent years was unprecedented. In this project, I finetuned some language models to make an unreliable news classifier.

In this article, we will discuss how to quickly showcase your model publicly as a machine learning application for free.

In this article, I will discuss a way of accessing Google Cloud GPUs to train your Deep Learning projects.

Code This case study is my capstone project for the Google Data Analytics Certification offered through Coursera. I was given access to …
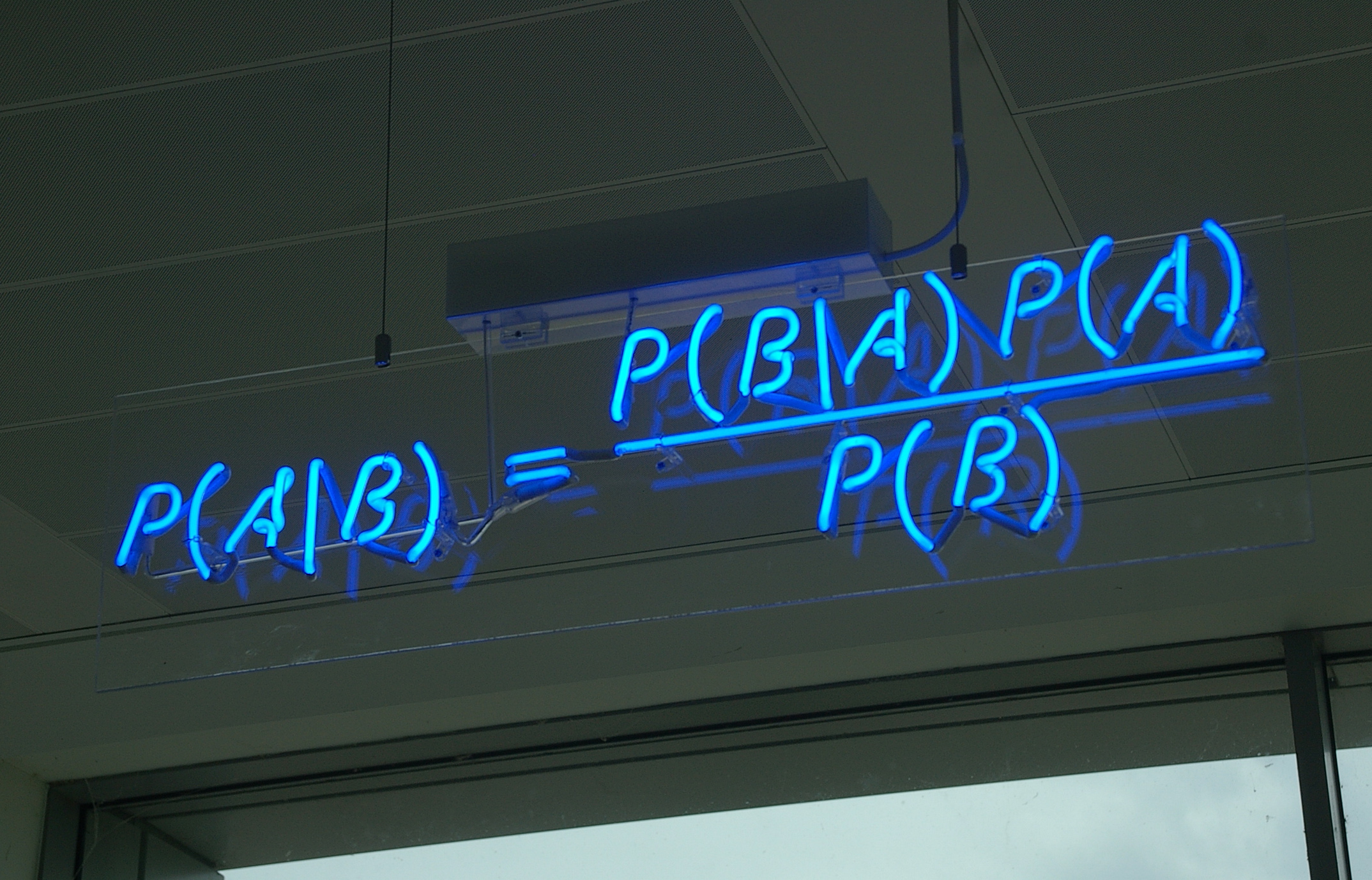
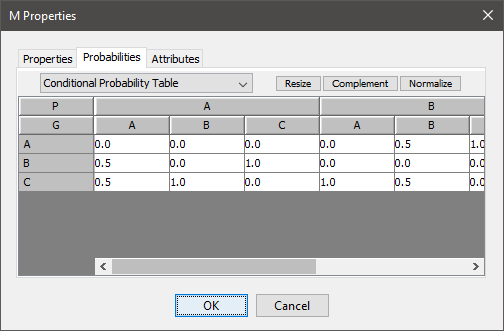
However, to make it a little bit more scalable, the tables are defined in a separate Google sheet, and imported into the Google Colab notebook. Each node is a separate worksheet, and the columns list the parent nodes, the name of the node, and probability.
Bayesian Networks are a compact graphical representation of how random variables depend on each other. It can be used to demonstrate the …

In this article we will break down what the Fourier Transform does to a signal, then we will be using Python to compute and visualize the transforms of different waveforms.